
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 컴파일러
- docker
- 정보검색
- 자연어처리
- 오픈소스웹소프트웨어
- css
- 파싱테이블
- 소프트웨어공학
- React
- 836
- 웹소프트웨어
- OS
- 랩실일기
- 프로세스
- C언어
- 데이터분석
- 도커
- 운영체제
- DB
- NLP
- 데이터베이스
- 컴파일
- 객체지향설계
- 자료구조
- Linear Algebra
- 파싱
- 언어모델
- 스케줄러
- 클래스
- 가상메모리
- Today
- Total
observe_db
[NLP] 3. 형태소 분석(Morphological Analysis) 본문
어절: 한국어에서는 띄어쓰기, 영어에서는 단어 단위(word phrase). 한 개 이상의 형태소로 구성.
음절(Syllable): 말하고 듣는 가장 작은 발화의 단위. Character라고도 함. 자소와 명확한 구분을 위해 음절 사용.
자소: 한 음절을 이루는 자음 및 모음. (한국어에서) 초,중,종성 구분.
코드: 글자와 숫자(코드)의 mapping을 표준으로 정한 것.
영문용 7비트 코드(ASCII)
영문 확장용 8비트 코드: 유럽 글자나 그래픽코드 등을 위해 확장. 여러 종류 글자세트 정의
ISO 10646, Unicode 등
한글 코드와 영문 코드
- 영문은 1바이트 내에 수용 가능.(알파벳 26자+숫자, 특수기호)
- 한글 코드는 코드 체계에 따라 바이트 수 필요.
- 기존 영문 코드와 충돌 방지 필요
- SI/SO나 MSB, prefix 코드 등을 사용
가변길이 조합형 코드(일명 n-바이트 코드)
- 자판의 영어 글자를 그대로 한글 자소로
- SI(Shift In), SO(Shift Out)을 이용하여 한글-영문 모드 변경
- 한글 음절 구분이 불편
- 다른 나라 코드와 충돌 가능성.
고정길이 조합형 코드
- 한 음절을 2바이트 코드에 대응
- 자소를 구분하기 위해 영역으로 구분
- MSB를 1로 설정
- 2바이트를 1+5+5+5로 분리 한/영+초+중+종
- 국제 통신 코드와 충돌
- 3바이트의 Unicode 조합형은 충돌없이 가능
완성형 코드
- 한 음절을 2바이트 코드에 대응
- 2바이트 모두의 MSB를 1로
- 고정 길이는 대부분 2~4바이트
- KSC 5601-1987, Unicode 대부분
- 자소를 쉽게 구분해 낼 수 없음.
- 국제 통신 코드와 충돌이 없도록 조정.
가변 길이 완성형 코드
- UTF8
- 유니코드 비효율성 개선
- 바이트 앞의 prefix 비트를 이용하여 연장 표시
- 많이 쓰이는 코드는 2바이트
- 자주 안쓸수록 길어짐(3바이트, 4바이트)
자소 분리
- 조합형: 자소 부분을 찾아 표준 코드로 변환
- 완성형: 자소가 구분되는 조합형 형태의 코드로 변환후, 자소 분리
- 어절: 한국어에서는 띄어쓰기, 영어에서는 단어 단위(word phrase). 한 개 이상의 형태소로 구성.
음절(Syllable): 말하고 듣는 가장 작은 발화의 단위. Character라고도 함. 자소와 명확한 구분을 위해 음절 사용.
자소: 한 음절을 이루는 자음 및 모음. (한국어에서) 초,중,종성 구분.
코드: 글자와 숫자(코드)의 mapping을 표준으로 정한 것.
영문용 7비트 코드(ASCII)
영문 확장용 8비트 코드: 유럽 글자나 그래픽코드 등을 위해 확장. 여러 종류 글자세트 정의
ISO 10646, Unicode 등
한글 코드와 영문 코드
영문은 1바이트 내에 수용 가능.(알파벳 26자+숫자, 특수기호)
한글 코드는 코드 체계에 따라 바이트 수 필요.
기존 영문 코드와 충돌 방지 필요
SI/SO나 MSB, prefix 코드 등을 사용
가변길이 조합형 코드(일명 n-바이트 코드)
자판의 영어 글자를 그대로 한글 자소로
SI(Shift In), SO(Shift Out)을 이용하여 한글-영문 모드 변경
한글 음절 구분이 불편
다른 나라 코드와 충돌 가능성.
고정길이 조합형 코드
한 음절을 2바이트 코드에 대응
자소를 구분하기 위해 영역으로 구분
MSB를 1로 설정
2바이트를 1+5+5+5로 분리 한/영+초+중+종
국제 통신 코드와 충돌
3바이트의 Unicode 조합형은 충돌없이 가능
완성형 코드
한 음절을 2바이트 코드에 대응
2바이트 모두의 MSB를 1로
고정 길이는 대부분 2~4바이트
KSC 5601-1987, Unicode 대부분
자소를 쉽게 구분해 낼 수 없음.
국제 통신 코드와 충돌이 없도록 조정.
가변 길이 완성형 코드
UTF8
유니코드 비효율성 개선
바이트 앞의 prefix 비트를 이용하여 연장 표시
많이 쓰이는 코드는 2바이트
자주 안쓸수록 길어짐(3바이트, 4바이트)
자소 분리
조합형: 자소 부분을 찾아 표준 코드로 변환
완성형: 자소가 구분되는 조합형 형태의 코드로 변환후, 자소 분리
형태소: 더이상 분해될 수 없는 최소한의 의미를 갖는 단위.
종류
- 실질 형태소: 구체적 대상이나 동작, 상태를 표시
- 형식 형태소: 실질 형태소에 붙어 관계를 표시(조사, 어미 등)
형태소 분석: 어절이 어떻게 형태소로 형성되어 있는 지를 분석하는 것(+자연어의 제약조건과 문법 규칙에 맞게)
한국어 형태소 분석
- 분석 대상: 어절
- 띄어쓰기 단위
- 하나 이상의 형태소가 연결된 것으로 어절을 형태소 열이라고도 부름
- 형태소 분석의 3단계
- 원형복원-분리-후보 선택
- 한국어 품사 태그 셋
- 분류 기준 및 원칙에 따라 서로 다른 품사 태그 셋 존재
- 언어학적 기준 차이
- 분류 정도에 따라 태그 셋 크기 다양
- 세종 품사 태그 셋: 국내 표준 마련.
규칙 기반 한국어 형태소 분석.
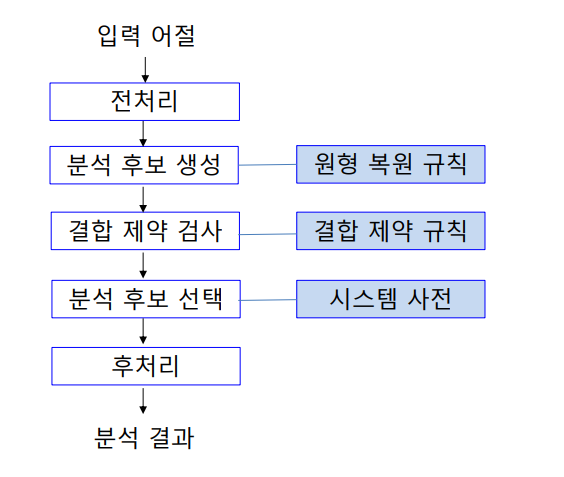
- 전처리
- 단어 추출, 문장 부호 분리
- 숫자/특수문자 처리
- 분석 후보 생성
- 형태소 후보 분리
- 불규칙 원형 복원
- 결합 제약 검사
- 모음 조화
- 형태소 결합 제약(음운 제약)
- 분석 후보 선택
- 사전 등재 확인
- 단어 형성 규칙
- 후처리
- 복합 명사 추정
- 미등록어, 준말 처리
분석 방법론
- 분석 방향
- 좌우(순방향), 우좌(역방향-어미나 조사 처리에 유리), 양방향
- 분석 방법
- Tabular 파싱, 최장 일치, 최단 일치, 음절 단위 분석
Tabular 파싱
- dynamic programming 기법으로 처리 속도 향상
- 한번 분석된 부분을 저장하여 사전 검색 횟수 최소화
- 코딩 좀 해본 분들은 피보나치 코드에서 이런 방법을 아실것..
- 상향식 파싱
- 단점
- 원형 복원으로 분석 도중 입력 길이나 원형이 변할 경우->처리하기가 복잡(표의 틀이 변형)
- 자소 단위 파싱의 경우, 무의미한 셀이 많이 등장.
한국어 형태소 분석의 어려움
- 모호성 있는 형태소 분석
- '나는'과 같이 여러 해석이 가능(날+는? 나+는?)
- 형태소의 변형이 일어나기 때문에 나타나는 현상
- 형태소 품사 모호성: 형태소는 하나 이상의 품사를 가질 수 있음
- 모호성은 문맥으로 해소됨--품사 태거의 역할
- 문법적 모호성 외에 의미적 모호성은 따로 처리
- 띄어쓰기의 일관성
- 복합어: 두개의 단어로 분석 가능
- 보조용언: 띄어쓰는 것을 원칙으로 하되, 경우에 따라 붙이는거 가능
- 준말 처리
- 구어체나 방언, 신조어 처리
- 외래어
'학교 공부 > 자연언어처리(4-2)' 카테고리의 다른 글
| [NLP] 6. 구문 분석 (5) | 2024.10.17 |
|---|---|
| [NLP] 5. 개체명 인식(Named Entity Recognition) (0) | 2024.10.10 |
| [NLP] 4. 품사 태깅 (1) | 2024.10.06 |
| [NLP] 2. 딥러닝 기초 (0) | 2024.10.03 |
| [NLP]1. 자연어처리 개요 (3) | 2024.10.03 |
