
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 정보검색
- css
- 파싱
- 언어모델
- NLP
- 오픈소스웹소프트웨어
- 운영체제
- 소프트웨어공학
- 가상메모리
- 836
- C언어
- 웹소프트웨어
- 데이터베이스
- OS
- 객체지향설계
- 데이터분석
- 랩실일기
- 컴파일러
- 스케줄러
- 컴파일
- 클래스
- 자연어처리
- Linear Algebra
- DB
- 프로세스
- 파싱테이블
- React
- docker
- 자료구조
- 도커
- Today
- Total
observe_db
[NLP] 6. 구문 분석 본문
구문 문법
- 구문 문법은 문장에 대한 구조 정보를 정의한 것
- 문장을 구성 요소들로 분석/구성 요소들을 문장으로 생성
- 구문의 모호성 해소
- ex. 구구조 문법, 의존 문법
구문 중의성(Syntax Ambiguity)
- 자연어 문장의 구문 구조가 여러가지 방법으로 분석 될 경우
- 중의성 해결을 위해 의미, 문맥 등의 추가적 정보가 필요
- 구문 분석 결과가 잘못되면 이후 단계에 오류 전파
대표적 구문 문법
구구조 문법(Phrase Structure Grammar, PSG)
- 노암 촘스키 제안
- 구성소 관계에 기반하여 문장 구조 분석
- 단어->구->더 큰 구, 이 계층 관계에 따라 문장 구성
- 문장 전체를 트리구조로 분석할 떄 단어와 구는 각 노드or부분 트리로 표현
의존 문법(Dependency Grammar)
- 뤼시엥 테니에르 제안
- 의존 관계에 기반하여 문장 구조 분석
- 문장을 구성하는 단어간 계층적 의존관계에 따라 문장이 이루어진다 분석
- 지배소와 의존소의 의존관계로 표현
- 문장 전체를 트리구조로 분석할 때 단어들은 각 노드, 엣지는 단어간 의존관계 표현
구구조 보다 의존 문법을 더 많이 사용하는 추세
-구구조는 영어 중심 언어에 제한적 활용(free word order 언어에 불리.)
2. 구구조 문법
=context free grammars(CFGs)
G = (T, N, S, R)
- T: terminal
- N: non-terminal
- S: start
- R: set of rules/productions of form X->r
- 문법 G는 언어 L을 생성한다
자연어 처리에서는
G = (T, P, N, S, L, R)
- T: terminal
- P: preterminal
- N: non-terminal
- S: start
- L: Lexicon
- R: grammar
- 빈 문자열은 빈칸 대신 대게 엡실론으로 표현
규칙 기반 구문 분석
구구조 구문 분석(Phrase Structure Parsing)
구구조 문법- 자연어 문장을 하위 구성소들로 나누어 문장 구조를 나타냄.
구성소: 한 개의 단위 같이 기능하는 일련의 단어들
ex. A->BC: A가 하위 구성소 B, C로 분석될 수 있음.
CYK 파싱 구현 순서
- 기존 문법을 Chomsky Normal Form으로 바꿈
- 이 문법으로 Table 기반 파싱 수행
CNF
- Epsilon 규칙 없음
- 1개의 비단말->2개의 비단말(A->BC)
- 1개의 비단말->1개의 단말(A->w)
통계 기반 구문 분석
: 구문 생성 규칙의 선택을 말뭉치 통계에 근거하여 처리
확률 계산은 조건부 확률로 계산.
- P(a->b | a) = Count(a->b)/Count(a)
(count는 말뭉치(코퍼스)에서 문법 규칙이 나타난 횟수)
구문 트리의 확률 계산
- 적용된 문법 규칙들의 조건부 확률을 모두 곱하여 계산
- 그 중 확률이 가장 높은 구문 구조 선택
P(T|S) = P(ai -> bi | ai)에서 모든 i에 대한 곱(파이)
T' = argmax_T(P(T|s))
전이 기반 구문 분석(Transition-based Parsing)
- 문장에서 한 단어씩 읽으며 현 단계에서 수행할 액션을 선택하는 방식
- 지역 정보를 중심으로 처리해서 전역적 처리 미흡
- 수행속도는 빠름
- Shift-reduce 파싱
- Shift: 단어를 스택에 이동
- Reduce: 단항/이항 감축-스택에 저장된 하나or두 개의 구성소를 꺼내 상위 구성소로 감축하고 스택에 이동
3. 의존 문법
의존 문법의 지배 관계
- 수식하거나 술어의 논항과의 관계 표현
- 지배소(head, governor)와 의존소(dependent, modifier)의 관계: 지배소->의존소
- 예시
- 관사, 형용사는 명사 수식
- 전치사는 명사를 수식하는 것으로 처리
- 전치사구는 명사구 수식
- 주 명사구는 동사의 논항
의존문법 트리
- 의존 트리의 시작으로 ROOT 노드 사용
- 구둣점 포함 가능
- (예시)
구문구조-의존 문법 트리
- 두 어휘 사이의 비대칭 이진 관계(의존 관계)로 구문 구조 파악
- 중심어(지배소)가 루트 부근에 있어 핵심 구조 쉽게 파악
- 의존 관계에 문법관계(주, 목)가 포함되기도 함.
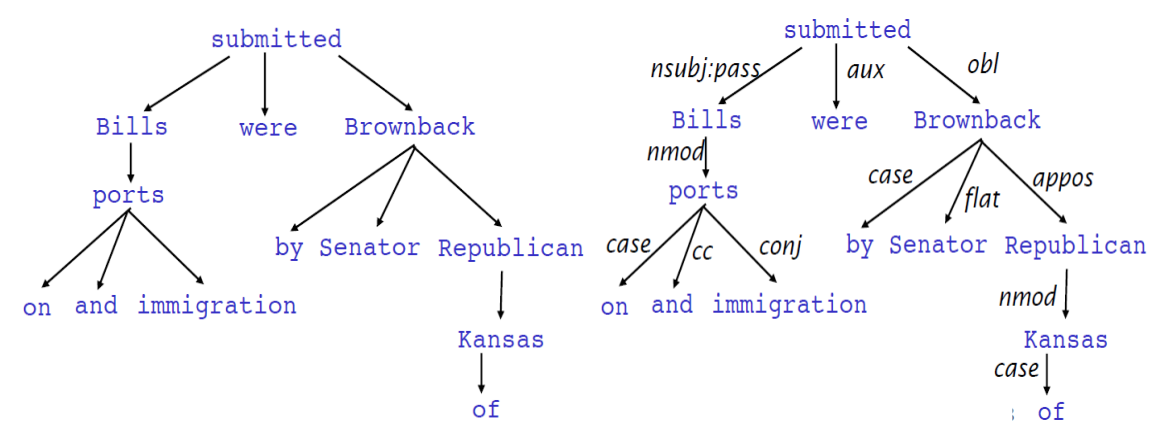
의존관계의 선호
- 두 어휘 사이의 친화도
- 의존 거리: 대부분 근처 단어
- 가로질러 가기: 거의 없음(의존 관계가 동사나 구둣점을 가로질러 가는 경우)
- 지배소의 의존소 포함 개수: 동사의 경우, 대 일정 숫자로 제한
투사성(projectivity)
: 문장의 단어들 사이의 의존 관계 화살표를 가로질러 가는 것이 있으면 안된다.
: CFG(구구조 문법)와 대응관계를 유지하려면 투사성이 있어야함.
비투사성
: 의존 문법 이론에서는 비투사성을 허용함
이동된 구성성분에 대한 처리를 위해 허용
이 경우, 비투사성 의존 관계 없이는 구성 성분의 의미 관계를 찾을 수 없음.
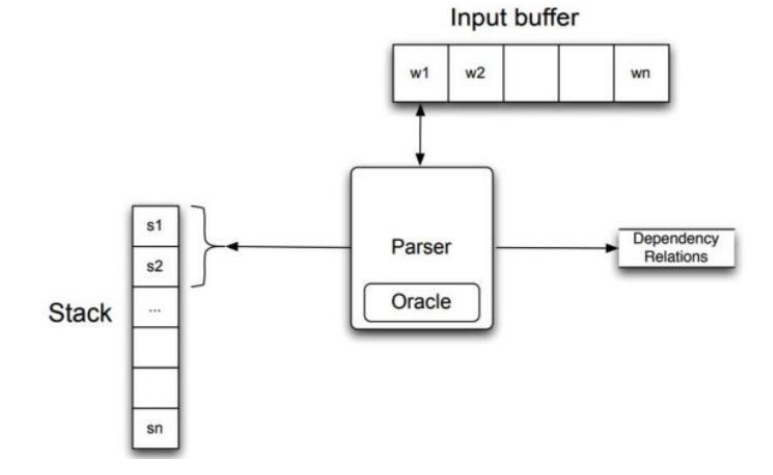
전이 기반 의존 구문 분석
-기본
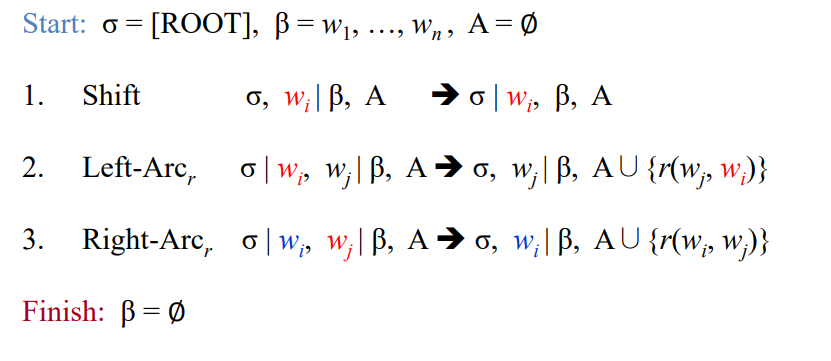
- 여기서 시그마는 stack구조, B는 입력 단어들, A는 의존관계를 저장하는 set(집합)
- Shift는 B의 단어 wi를 시그마에 넣는 연산
- Left-Arc는 시그마에 있는 단어 wi를 B의 단어 wj의 의존소로 설정하여 A에 넣는 연산.(화살표가 왼쪽으로 향함)
- Right-Arc는 시그마에 있는 단어 wi를 B의 단어 wj의 지배소로 설정하여 A에 넣는 연산.(화살표가 오른쪽으로 향함)
- B가 공집합이 되면 종료.
-arc-eager 의존 파서

대부분은 동일하지만
- Left-Arc에 선수조건: wk와의 wi가 의존관계가 있으면 안된다., wi가 루트여도 안된다.(둘다 불가능)
- Right-Arc에서: wi와 wj를 모두 시그마에 넣는다.
- Reduce: 시그마에서 wi를 제거한다. +선수조건: wk와 wi의 의존관계가 있을 때에.
그래프 기반 파싱(Graph-based Parsing)
- 자연어 문장에 포함된 단어 간 가능한 모든 관계에 대한 점수를 계산
- 문장 전체에서 가장 높은 점수를 갖는 분석 결과 선택
- 딥러닝 모델을 통해 각 관계의 점수 예측
- 전이 기반 파싱에 비해 문장 전체(전역적) 문법 구조를 고려할 수 있음
- 상대적으로 시간 복잡도 높음.
- MST(Maximum Spanning Tree)로 해결.
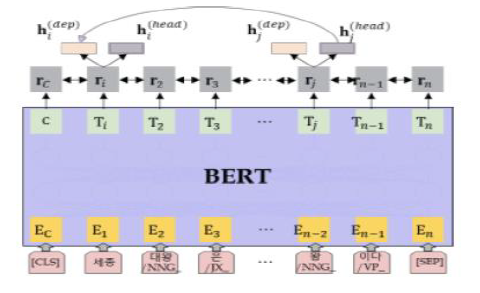
BERT와 biaffine attention을 이용한 의존 구문 분석
- biaffine attention: 두 어휘(단어) 사이 친밀도 계산(지배소-의존소)
- 언어 모델의 강력한 학습 능력을 이용
- BERT의 사전학습 기능을 이용하여 각 단어의 잠재 벡터를 출력하고 이를 biaffine attention 학습에 사용.
'학교 공부 > 자연언어처리(4-2)' 카테고리의 다른 글
| [NLP] 8. 의미역 분석 (0) | 2024.11.01 |
|---|---|
| [NLP] 7. 단어 의미 모호성 해소 (0) | 2024.11.01 |
| [NLP] 5. 개체명 인식(Named Entity Recognition) (0) | 2024.10.10 |
| [NLP] 4. 품사 태깅 (1) | 2024.10.06 |
| [NLP] 3. 형태소 분석(Morphological Analysis) (0) | 2024.10.04 |


