
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 소프트웨어공학
- 컴파일러
- 데이터분석
- 자료구조
- 웹소프트웨어
- 스케줄러
- React
- NLP
- 정보검색
- Linear Algebra
- 랩실일기
- C언어
- 도커
- 운영체제
- 오픈소스웹소프트웨어
- DB
- 836
- docker
- 언어모델
- 파싱테이블
- css
- 객체지향설계
- 데이터베이스
- 가상메모리
- 파싱
- 클래스
- 컴파일
- 자연어처리
- 프로세스
- OS
- Today
- Total
observe_db
[NLP] 7. 단어 의미 모호성 해소 본문
10/30
단어 의미 모호성 해소(Word-sence disambiguation)
: 문장 내에서 모호성을 가지는 어휘를 사전에 정의된 의미와 매칭하여 어휘적 모호성을 해소하는 문제

문제 정의
어휘 비교 방법
- 레스크 알고리즘
- 어휘 의미망 기반 방법
- 분류 기반 방법(어휘 자질 벡터 비교 방법 포함)
벡터 비교 방법(dence vector)
- 딥러닝 기반 분류 방법
- 압축된 의미 레이블 기반 분류 방법
- 문맥과 의미 정의 문맥 비교
- 문맥 벡터와 의미 정의 벡터 비교
Lesk 알고리즘(Lesk, 1986)
: 단어의 사전 뜻풀이에 쓰인 단어들과 의미적 모호성이 있는 단어 주변 문맥에 나타난 문맥 패턴 또는 중복된 단어 수를 보고 의미를 결정하는 방법
과정
- 단어 선택(select word)
- 문맥 범위 정의(Define context windows)
- 정의 비교(Compare definitions)
- 겹치는거 계수(Count overlaps)--a, the 같은건 제외
- 가장 많이 겹치는 정의로 선택(Choose most overlapping definition)
그래프 기반 방법
: 주변 문맥에 나온 단어들의 어휘 의미망 부분 그래프를 추출하고 그중 가장 연결성이 높은 단어의 의미를 선택
어휘 의미망 사전에 정의된 관계성만 고려함
예시: She drank some milk.
- 모호한 단어인 drink, milk의 synset을 Wordnet에서 추출 (특정 거리는 미리 정의)
- 탐색 알고리즘(DFS/BFS)으로 edge를 추출하여 subgraph 생성
- 가장 많이 연결된 의미를 선택.
분류 기반 방법
말뭉치 기반 지도 학습
: 각 단어에 의미 Labeling이 부착된 데이터(학습 데이터)를 이용
의미 모호성 단어의 의미 레이블을 주변 문맥 단어들의 정보를 기반으로 분류
학습 데이터의 의미 레이블에 한정될 수 있음.
나이브 베이즈 분류기(Naive Bayes Classifiers, NB)
: 특정 범주에 출현한 자질의 확률 통계를 사용
: NB 분류기의 식(c:의미, x:문장, v: 문장 내 단어)
c = argmax P(ck|x)
= argmax P(ck)*P(x|ck)/P(x) ---Bayes 정리에 의해 치환
= argmax P(ck)*P(x|ck) --P(x)=1이므로
= argmax[logP(x|ck) + logP(ck)] --log 사용
= argmax[Sigma(vj in x) log P(vk|ck) + log P(ck)]
kNN(k-Nearest Neighbor Classifiers)
: 벡터 공간에 표현된 자질들이 정해진 k값에 따라서 가장 많이 묶이는 자질들의 의미 클래스 선택
자질을 묶기 위해 유클리드 거리나 코사인 유사도를 주로 사용한다.
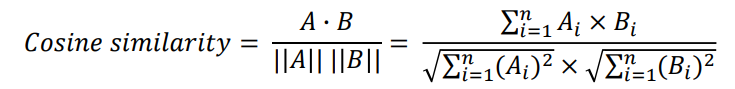
SVM(Support Vector Machine)
: 벡터 공간에 표현된 자질로부터 의미 클래스를 분류하기 위해 클래스간 가장 넓은 거리를 사용하는 방향으로 선을 그어 의미 분류
잡음 자질이나 자질 결합의 크기가 커도 좋은 성능을 보임
'학교 공부 > 자연언어처리(4-2)' 카테고리의 다른 글
| [NLP] 9. 정보 추출 (0) | 2024.11.01 |
|---|---|
| [NLP] 8. 의미역 분석 (0) | 2024.11.01 |
| [NLP] 6. 구문 분석 (5) | 2024.10.17 |
| [NLP] 5. 개체명 인식(Named Entity Recognition) (0) | 2024.10.10 |
| [NLP] 4. 품사 태깅 (1) | 2024.10.06 |


