
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 객체지향설계
- 자료구조
- 자연어처리
- 운영체제
- 스케줄러
- OS
- 데이터베이스
- NLP
- 파싱테이블
- 소프트웨어공학
- 컴파일러
- C언어
- 가상메모리
- css
- 컴파일
- 도커
- 랩실일기
- docker
- 프로세스
- 데이터분석
- 오픈소스웹소프트웨어
- React
- 파싱
- 클래스
- 836
- 정보검색
- 언어모델
- Linear Algebra
- 웹소프트웨어
- DB
- Today
- Total
observe_db
[자료구조] 그래프(Graph) 본문
그래프의 추상 타입(The Graph Abstract Data Type)
시초는 오일러의 쾨인스버그 다리 문제래프의 추상 타입(The Graph Abstract Data Type)
시초는 오일러의 쾨인스버그 다리 문제
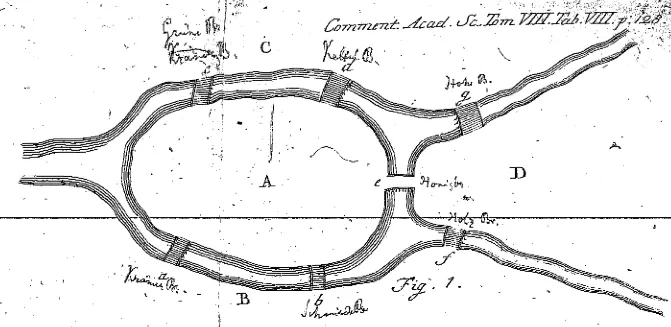
임의의 지역에서 출발하여 모든 다리를 단 한번씩만 지나 처음 출발한 지역으로 되돌아 올 수 있는가?
- 각 정점(vertex)의 차수가 짝수이면 가능.
차수(degree): 정점에 연결된 간선 수
오일러 행로(Eulerian walk)
정의(definition)
그래프 G: 2개의 집합 V와 E로 구성
- V: 공집합이 아닌 정점(vertex)의 유한집합
- E: 간선(Edges), E ⊆{{x, y} | (x, y) ∈ V^2 ∧ x!=y}
- 표기: G=(V,E)
무방향 그래프(undirected graph): 간선을 나타내는 정점의 쌍에 순서 없음
방향 그래프(directed graph): 방향을 가지는 정점의 쌍 <u, v>로 표시 (u는 꼬리(tail), v는 머리(head))
그래프의 제한 사항(Graph를 Set으로 정의한 경우)
- 자기 간선(self edge) 또는 자기 루프(self loop) 없음
- 동일 간선의 중복 없음. (단 다중그래프(multigraph)는 이 제한이 없음)
완전 그래프(complete graph): n개의 정점과 n(n-1)/2개(n개 vertex가 자신을 제외한 n-1개의 vertex에 연결. 무방향이므로 /2)의 간선(edge)을 가진 그래프
Adjacent(인접)
- (u, v)가 E(G)의 한 간선이라면 u와 v는 인접(adjacent)한다.
- 간선 (u, v)는 정점 u와 v에 부속(incident)된다.
그래프 G의 부분 그래프(subgraph)
- V(G') ⊆ V(G) 이고 E(G') ⊆ E(G)인 그래프 G'
u, v까지 경로 path
무방향 그래프의 경우
- (u, i1), (i1, i2)...(ik, v)를 E(G)에 속한 간선
-정점열(sequence of vertices) u, i1, i2....ik,v를 말함
방향 그래프의 경우
-G'이 방향 그래프이면 경로는 E(G')에 속한 간선들로 구성
- <u, i1>, <i1, i2>...<ik, v)
경로의 길이(length): 경로 상에 있는 간선의 수
단순 경로(simple path): 경로상에서 청므과 마지막을 제외한 모든 정점이 서로 다름
사이클(cycle): 처음과 마지막 정점이 같은 단순 경로
connected(연결되었다): G에서 정점 u부터 v까지 경로가 있다면, 두 정점 u와 v는 연결되었다고 한다.
연결 요소(connected component)-최대 연결 부분 그래프: 연결되어있고, H를 포함한 또 다른 부분 그래프가 G에 존재하지 않음.
강력 연결 요소(strongly connected component)
: 강하게 연결된 최대 부분 그래프
방향 그래프에서 vertex u, v에 대해 u->v, v->u로 경로가 존재하면 강력 연결.
Acyclic (no cycle) Graph = Tree: 그래프 관점에서 트리는 사이클이 없는 연결 그래프
차수(degree): 정점에 부속한 간선의 수
진입 차수(in-degree): 임의의 정점 v가 머리(head)가 되는 간선들의 수
진출 차수(out-degree): 임의의 정점 v가 꼬리(tail)가 되는 간선들의 수
간선의 수:

다이그래프(digraph): 방향 그래프
digraph(directed) <-> graph(undirected)

그래프 표현법
1. 인접 행렬(Adjacency Matrix): vertex 중심
2. 인접 리스트(Adjacency List): vertex 중심 연결 리스트
3. 인접 다중 리스트(Adjacency Multilist): edge 중심
인접 행렬: n*n의 2차원 배열
- 간선 (vi, vj)∈E(G) => a[i][j] = 1
- 간선 (vi, vj)!∈E(G) => a[i][j] = 0
- 필요 공간: n^2 비트(공간)
무방향 그래프에서 어떤 정점 i의 차수는 그 행의 합
방향 그래프에서 행의 합은 진출 차수, 열의 합은 진입 차수
간선 수 계산, G가 연결되었는지 검사 시간
- n^2 - n개의 항을 계싼
- O(n^2)
희소 그래프: O(e+n)
- e << n^2/2
- G의 간선만을 저장하는 별도의 정보가 필요
인접 리스트
- 인접 행렬의 n행들을 n개의 chain으로 표현
- 무방향 그래프: n개의 헤드노드, 2e개의 리스트 노드가 필요.(e는 vertex 수)
- 방향 그래프: n개의 헤드노드, e개의 리스트 노드
순차 리스트(array) 사용: node[n+2e+1]
- 정점 i와 인접한 정점: node[i]....node[i+1]-1에 저장
역인접리스트(inverse adjacency lists)
-vertex의 진입차수를 구하기 위한 자료구조
-진입차수가 복잡하므로 이를 해결하기 위함
- 리스트가 표현하는 정점에 인접한 각 정점에 대해 하나의 노드를 둠
직교 리스트(orthogonal list)
- 간선(edge)이 적은 그래프의 인접리스트에 대한 표현
- 희소 행렬(sparse matrix)에 사용한 자료구조 차용
인접다중 리스트(Adjacency Multilists)
인접 리스트의 문제점
- 간선(u, v)는 두 개의 엔트리로 표현
- u를 위한 리스트, v를 위한 리스트에 나타남
vertex 중심 인접 리스트를 edge 중심 리스트로 변경

가중치 간선(weighted Edges)
- 그래프 간선에 가중치(weights)
- 인접 행렬: 행렬 엔트리에 a[i][j]의 가중치 정보 저장
- 인접 리스트: 노드 구조에 weight 필드를 추가
그래프의 기본연산(Elementary Graph Operations)
깊이 우선 탐색(Depth First Search, DFS)
- Tree의 preorder traversal과 유사
- 차이점
- [tree] parent, left-child, right-child를 구분
- [graph] parent-child 구조가 아님->유일하게 결정되지 않음, edge수 제약 없음.
- 방문 여부를 기록해야함. (visit flag)
DFS-iterative
1) 시작 정점 v를 결정: visit mark & push(v)
2) w = adjacent(top())
- 방문하지 않은 정점 w가 존재: push(w) & visit mark
- 방문하지 않은 정점 w가 없음: pop()
3) goto 2), 스택이 공백이 되면 종료
DFS-recursive
void dfs(int v)
{
nodePointer w;
visited[v] = TRUE;
printf("%5d", v);
for(w=graph[v]; w; w=w->link){
if(!visited[w->vertex]) dfs(w->vertex);
}
}
Adjacency List 사용시: 탐색 끝내는 시간 O(e)
Adjacency Matrix 사용시: 인접 정점들을 찾는 시간: O(n), 총 시간 O(n^2)
너비 우선 탐색(Breath First Search, BFS)
- tree의 level-order traversal과 유사
- 차이점
-
- [tree] parent, left-child, right-child를 구분
- [graph] parent-child 구조가 아님->유일하게 결정되지 않음
BFS-iterative
1) 시작 정점 v를 방문: visit marking & enqueue()
2) w = dequeue(): visit marking & 방문하지 않은 w의 인접 노드 enqueue()
3) goto 2), queue가 empty이면 종료
void bfs(int v)
{
node_pointer w;
queue_pointer front, rear;
front = rear = NULL; //큐 초기화
printf("%5d", v);
visited[v] = TRUE;
addq(&front, &rear, v);
while(front){
v = deleteq(&front);
for(w=graph[v]; w; w=w->link){
if(!visited[w->vertex]) {
prinf("%5d", w->vertex);
addq(&front, &rear, w->vertex);
visited[w->vertex] = TRUE;
}
}
}
}Adjacency List 사용시: 탐색 끝내는 시간 O(e)
Adjacency Matrix 사용시: 인접 정점들을 찾는 시간: O(n), 총 시간 O(n^2)
연결 요소(Connected Components)
무방향 그래프의 연결 여부 검사
- dfs(0) 또는 bfs(0)으로 vertex 호출
- 종료 시 방문이 안된 vertex가 존재하는지 검사
연결요소: 방문하지 않은 정점 v에 대해 dfs(v) 또는 bfs(v)를 반복호출로 구함
void connected(void)
{
int i;
for (i=0; i<n; i++){
if(!visited[i]){
dfs(i);
prinf("\n");
}
}
}
연결 분석
- 인접 리스트 이용: 모든 연결 요소 나열하는 시간은 O(n+e)
- 인접 행렬 이용: O(n^2)
신장 트리(Spanning Tree): G의 간선들로만 구성되고 G의 모든 정점들이 포함된 트리
- 깊이-우선 신장 트리 & 너비-우선 신장 트리
- 궁극적인 목적은 cycle 제거(acyclic)
ex. 네트워크의 Spaaning Tree Protocol
신장트리는 G의 최소부분 그래프 G'로서 V(G') = V(G)이고 G'는 연결되어있음.
* 최소의 의미는 모든 vertex의 연결+edge 수가 최소. 신장 트리는 n-1개의 간선을 가짐
이중 결합 요소(Biconnected Components)
- 단절점(articulation point): 그래프의 정점들 중 이 정점과 그에 부속한 모든 간선을 삭제 시, 최소한 두 개의 연결 요소를 만드는 정점
- 이중 결합 그래프(biconnected graph): 단절점이 없는 연결 그래프. 2개이상의 vertex가 연결되어있음.
최대 이중결합 부분그래프
이중 결합 요소
- Tree edge: tree의 edge와 동일한 역할. DFS할 때에 사용됨
- Forward edge: DFS tree에는 속하지 않으나, 트리를 내려가는 edge(사진에선 <1,8>)
- Back edge: DFS tree에는 속하지 않고, 트리를 올라가는 edge(사진에선 <6,2>)
- Cross edge: 조상-자손에 속하지 않는 두 노드간 연결(사진에선 <5,4>)

연결 무방향 그래프의 이중 결합 요소
- 깊이 우선 신장 트리 이용
if u가 v의 조상이면, dfn(u) < dfn(v)
단절점 조건
1) u가 root이고, 2개의 child vertex 존재
2) u의 child인 w가 존재하고 w에서 path를 통해 u의 조상으로 접근할 수 없는 경우
low(u): u의 후손들과 많아야 하나의 백 간선을 된 경로를 이용해 u로부터 도달할 수 있는 가장 적은 깊이 우선번호(dfn)
low(u) = min{ dfn(u), min{low(w) | w는 u의 자식}, min{dfn(w) | (u,w)는 백 간선}}
void dfnlow (int u, int v)
{/* compute dfn and low while performing a dfs search beginning at vertex u, v is the parent of u (if any) */
nodePointer ptr;
int w;
dfn[u] = low[u] = num++;
for (ptr = graph[u]; ptr; ptr = ptr->link) {
w = ptr->vertex;
if (dfn[w] < 0) { /* w is an unvisited vertex */
dfnlow(w, u);
low[u] = MIN2(low[u], low[w]);
}
else if (w != v) low[u] = MIN2(low[u], dfn[w]);
}
}
최소 비용 신장 트리(Minimum Cost Spanning Trees)
without any cycles and with the minimum possible total edge weight
: 최저의 비용을 가지는 신장트리
Kruskal, Prim, Sollin 알고리즘- Greedy method 사용 (optimal은 아니라도, 그에 근접할 수 있음)
- 주어진 위치에서 최선의 값을 선택
- 판단 기준에 따라 가장 좋은 값을 결정
신장트리의 제한 조건
1) 그래프 내에 있는 간선들만을 사용
2) 정확하게 n-1개의 간선만을 사용
3) 사이클을 생성하는 간선을 사용 금지
Krusakal's Algorithm
1. 하나씩 T에 간선을 추가해가면서 최소 비용 신장트리 T를 구축
2. T에 포함될 간선을 비용의 크기 순으로 선택
3. T에 포함된 간선과 사이클을 만들지 않는 간선을 T에 추가
4. n-1개의 간선만이 T에 포함됨
T = {};
while((T가 n-1개 미만의 간선 포함) && (E가 공백이 아님)){
E에서 최소 비용 간선(v,w) 선택;
E에서 (v,w) 삭제;
if(v,w)가 T에서 사이클을 만들지 않음
add(v,w) to T;
else
discard(v,w);
}
if T가 n-1개 미만의 간선을 포함
printf("No spanning tree\n");
Prim's Algorithm
1. 한번에 한 간선씩 최소 비용 신장 트리를 구축
2. 각 단계에서 선택된 간선의 집합은 트리
3. 하나의 정점으로 된 트리 T에서 시작
4. 최소 비용 간선 (u,v)를 구해 T ∪ {(u,v)}이 트리가 되면 T에 추가
5. T에 n-1개의 간선이 포함될 때까지 간선의 추가 단계를 반복
6. 추가된 간선이 사이클을 형성하지 않도록 각 단계에서 간선 (u,v)를 선택할 때 u 또는 v중 오직 하나만 T에 속한 것을 고른다.
T = { }; /* Minimum Cost Spanning Tree */
TV ={0}; /* 정점 0으로 시작. 간선은 비어 있음.*/
while(T의 간선수가 n-1보다 적음) {
u ∈ TV이고 v TV인 최소 비용 간선을 (u, v)라 함;
if (그런 간선이 없음)
break;
v를 TV에 추가;
(u, v)를 T에 추가;
}
if (T의 간선수가 n-1보다 적음)
printf (“신장트리 없음\n”);
Sollin's Algorithm
1. 각 단계에서 여러 개의 간선을 선택 (*큰 차이점)
2. 그래프의 모든 정점만 남김
3. 각 정점에서 가장 최소 비용 간선을 선택
4. 3번을 반복, 하나의 트리만 존재하거나 선택할 간선이 없으면 종료
최단 경로와 이행적 폐쇄
최단경로&이행적 폐쇄를 위한 2가지 질문
1. A에서 B로 가는 길이 존재하는가?(길/답의 존재성)
2. 그 길이 2개 이상이라면 어느 길이 최단인가?(최단경로/최적의 해)
음이 아닌 간선 비용(nonnegative edge cost)
- 시작 정점 v에서부터 G의 모든 다른 정점까지의 최단 경로를 구하는 것
하나의 출발점/모든 목표점
다익스트라 알고리즘(Dijkstra Shortest Path)
제약조건
1) edge의 weight >=0
2) acyclic graph (if digraph)
Relaxation
if(d[u]+c(u,v) < d[v]){
d[v] = d[u] + c(u,v)
}
집합 S: v0를 포함하여 최단 경로가 발견된 집합
distance[w]: v0에서 S에 있는 정점만을 거쳐 w로 끝나는 최단 경로의 길이
경로의 길이를 크기 순으로 생성할 경우,
next vertex u에 대해서
- v0에서 u로의 경로는 오직 S에 속한 정점만을 통과한다.
- S에 속하지 읺은 최소 거리의 distance[u]를 갖는 것으로 선택.
- v0에서 u로의 최단경로를 생성했다면, u는 S의 원소가 된다
// Time complexity: O(n^2)
void shortestPath(int v, int cost[][MAX_VERTICES]), int distance[], int n, short int found[])
{
int i, u, w;
for (i = 0; i < n; i++) {
found[i] = FALSE;
distance[i] = cost[v][i];
}
found[v] = TRUE;
distance[v] = 0;
for (i = 0; i < n-2; i++) {
u = choose(distance, n, found);
found[u] = TRUE;
for (w = 0; w < n; w++){
if (!found[w]){
if (distance[u] + cost[u][w] < distance[w]) distance[w] = distance[u] + cost[u][w];
}
}
}
}
문제는 방향그래프 G가 음수를 가지는 경우
- Dijkstra는 정상 동작하지 않음
- 음수 길이 사이클이 존재할 경우 최단 길이 경로가 존재하지 않는다.
동적 프로그래밍으로 최단 경로 찾기
- 모든 것을 기록하여 재활용한다.
- cycle이 존재하지 않으나, negative weight를 갖는 G의 최단경로
동적 프로그래밍 방법
- 모든 u에 대해 dist_n-1[u]를 구함(출발점 v에서 u까지 최단 경로)
- dist_k[u] = min{dist_k-1[u], min{dist_k-1[i] + length[i][u]}}
최단 거리를 구하는 Bellman -Ford 알고리즘
void BellmanFord(int n, int v)
{
for (int i = 0; i < n; i++)
dist[i] = length[v][i];
for (int k = 2; k <= n-1; k++)
for (each u such that u != v and u has at least one incoming edge)
for (each <i, u> in the edge)
if (dist[u] > dist[i] + length[i][u]) dist[u] = dist[i] + length[i][u];
}인접 행렬 사용시 O(n^3)
인접 리스트는 O(ne)
+cyclic graph의 length가 음수이면 적용이 안되므로 -> cyclic인지 검출에 적용할 수도 있음.
모든 쌍의 최단 경로
- u!=v인 모든 정점 쌍 u와 v간의 최단 경로를 구하는 것
- 연속적으로 A(-1), A0, A1...A(n-1)을 생성하는 것
- 동적 프로그래밍을 이용하여 생성
- Ak[i][j]: 인덱스 가 k보다 큰 정점을 통과하지 않는 i에서 j까지의 최단 경로의 비용-> k번 이내의 node를 이용한 최단 경로
- A(n-1)[i][j]: G의 어떠한 정점도 n-1보다 큰 인덱스가 없다 -> i에서 j까지 최단 경로비용 = A(n-1)[i][j]
A(k-1)이 이미 생성되었다면, Ak
- Ak[i][j] = A(k-1)[i][j]: i에서 j까지의 최단경로가 인덱스가 k인 정점을 통과하지 않으면 그 길이는 A(k-1)[i][j]
- i에서 j까지 최단경로가 k를 통과한다면
- i에서 k까지의 경로와 k에서 j까지의 경로로 구성
- i에서 k까지, 또, k에서 j까지의 부분 경로 둘 다 k-1보다 큰 인덱스를 가진 정점을 통과하지 않음
- 이 경로들의 길이는 A(k-1)[i][k], A(k-1)[k][j]가 된다
void allcosts (int cost[][MAX_VERTICES], int distance[][MAX_VERTICES], int n)
{ /* 각 정점에서 다른 모든 정점으로의 거리 계산,
cost[][] = adjacency matrix, distance[i][j] = i -> j shortest length*/
int i, j, k;
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
distance[i][j] = cost[i][j];
for (k = 0; k < n; k++)
for (i = 0; i < n; i++)
for (j = 0; j < n; j++)
if (distance[j][k] + distance[k][j] < distance[i][j]) distance[i][j] = distance[i][k] + distance[k][j];
}
Time complexity: O(n^3)
최단경로&이행적 폐쇄를 위한 2가지 질문
1. A에서 B로 가는 길이 존재하는가?(길의 존재성)
2. 그 길이 2개 이상이라면 어느 길이 최단인가?(최단경로)
이행적 폐쇄
Reachability
- 방향 그래프에서 한 정점에서 다른 정점에 도달 간으성
- DFT를 통해 정점에 도달 가능성을 검사 가능
Transitive Closure
- 가중치가 없는 방향 그래프 G의 모든 정점 i와 j에 대해서 i에서 j로의 경로가 존재하는지 결정 하는 문제
이행적 폐쇄 행렬(A+, transitive closure matrix) //경로 길이가 양인 경우만
- i에서 j로의 경로 길이 > 0 -> A+[i][j] = 1
- i에서 j로의 경로 길이 <= 0 -> A+[i][j] = 0
반사 이행적 폐쇄 행렬(A*, reflexive transitive closure matrix) //경로 길이가 음이 아닌 경우 허용(self loop 포함)
- i에서 j로의 경로 길이 >= 0 -> A*[i][j] = 1
- i에서 j로의 경로 길이 < 0 -> A*[i][j] = 0
//Warshall Algorithm
void warshall(graph g)
{
for (x = all vertices) {
for (y = all vertices) {
if (x -> y is reachable) {
for (z = all vertices) {
if (y -> z is reachable) x -> z is reachable;
}
}
}
}
}'학교 공부 > 자구(2-1)' 카테고리의 다른 글
| [자료구조] 해싱(Hashing) (0) | 2025.01.19 |
|---|---|
| [자료구조] 정렬(Sorting) (0) | 2025.01.19 |
| [자료구조] 힙(Heaps) (0) | 2025.01.06 |
| [자료구조] 트리(Trees) (0) | 2025.01.03 |
| [자료구조] 연결 리스트 (Linked Lists) (1) | 2025.01.02 |


