
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- 컴파일
- 도커
- React
- 컴파일러
- DB
- 클래스
- 언어모델
- 정보검색
- css
- 객체지향설계
- 가상메모리
- 자연어처리
- Linear Algebra
- 836
- 운영체제
- 데이터베이스
- 웹소프트웨어
- 데이터분석
- 오픈소스웹소프트웨어
- 파싱
- 스케줄러
- OS
- 자료구조
- 프로세스
- 소프트웨어공학
- 파싱테이블
- 랩실일기
- docker
- NLP
- C언어
- Today
- Total
observe_db
[자료구조] 정렬(Sorting) 본문
용어
레코드(record): 여러 개의 field로 객체(object, 정보) 표현
리스트(list): 레코드의 집합(set)
키(key): 레코드를 구분하기 위한 필드
순차 탐색(Sequential Search or Linear Search): 레코드 리스트를 순차적으로 검사하는 것
안정성(Stability): 정렬의 각 pass를 수행할 때 key값에 대해 상대적으로 순서를 그대로 유지한다면 알고리즘은 stable하다고 함.
- 여러 개의 키를 우선순위를 정해서 정렬하는 경우 알고리즘 선택에 중요한 관건이 됨.
(다른 말로 단일 키엔 그닥 의미 없음)
순차 탐색
seqSearch(element a[], int k, int n)
{/* a[1:n]탐색; a[i].key = k를 만족하는 최소의 i를 반환. 없으면 0을 반환. */
int i;
for(i = 1; i <= n && a[i].key != k; i++)
;
if(i > n) return 0;
return i;
}Time Complexity: O(n)
평균 키 비교 횟수: (n+1)/2
이원 탐색(Binary search)
Time Complexity: O(log n)
보간법(Interpolation)\
- 리스트 정렬 시에만 사용 가능
- 리스트의 키의 분포 정보를 활용
- k를 a[i]와 비교 (i=midpoint)
- i = ((k-a[1].key) / (a[n].key-a[1].key))*n
리스트를 반복 탐색할 때 정렬된 상태로 유지하는 것이 전체적인 속도 개선
순차 탐색으로 두 리스트 검증
- 두개의 비 정렬 리스트를 직접 비교해서 검증 문제 해결
- O(mn)
- 정렬 시킨 다음 비교
- O(t_sort(n) + t_sort(m) +n +m)
= O(max(nlog n , mlog m))
다양한 정렬과 탐색
정렬
- 내부정렬(internal sort)
- insertion sort
- merge sort
- bubble sort
- radix sort
- selection sort
- quick sort
- shell sort
- tree sort
-외부정렬(external sort)
- merge sort ~ k-way merge sort
탐색
- sequential search = linear search
- binary search
- interpolation search
삽입 정렬(Insertion sort)
- 정렬 되어있는 부분집합에 새로운 원소의 위치를 찾아 삽입
- 두개의 부분 집합 S와 U로 가정 (Sorted Subset, Unsorted Subset)
- 부분집합 S: 정렬된 앞부분의 원소들
- 부분집합 U: 아직 정렬되지 않은 나머지 원소들
- 정렬되지 않은 부분집합 U의 원소를 하나씩 꺼내서 이미 정렬되어있는 부분집합 S의 마지막 원소부터 비교하면서 위치를 찾아 삽입
- 삽입 정렬을 반복하면서 부분집합 S의 원소는 하나씩 늘리고, U의 원소는 하나씩 감소하게 함.
- 부분집합 U가 공집합이 되면 삽입 정렬이 완성
/*
최악 경우: i+1번 비교,
Time complexity: O(i)
*/
void insert(element e, element a[], int i)
{
a[0] = e;
while(e.key < a[i].key)
{
a[i+1] = a[i];
i--;
}
a[i+1] = e;
}
/*
Time complexity: O(n^2)
*/
void insertionSort(element a[], int n)
{
int j;
for(j = 2; j <= n; j++) {
element temp = a[j];
insert(temp, a, j-1);
}
}
최악은 입력 리스트가 역순일 경우
삽입 정렬은 안정적(stable)
작은 n(약 30이하)에 대해 가장 빠른 정렬 방법
선택정렬(Selection Sort)
가장 간단한 알고리즘, 실생활에 가장 많이 사용하는 알고리즘
방법
- 주어진 리스트 중에 최소값을 찾는다
- 그 값을 맨 앞에 위치한 값과 교체
- 맨 처음 위치를 뺀 나머지 리스트를 같은 방법으로 교체한다.
Time complexity: O(n^2)
메모리 제한적인 경우 사용시 성능상의 이점 (In-place sorting algorithm)
버블(거품)정렬(Bubble Sort)
인접한 배열의 요소를 비교 교환하여 전체적으로 대충 정렬을 하면서 최대값을 배열의 제일 뒤로 보내는 것을 반복
정렬 방식
- 첫 원소부터 마지막 원소까지 반복하여 한 단계가 끝나면 가장 큰 원소가 마지막 자리로 정렬
- 첫 원소부터 인접한 원소끼리 계속 자리를 교환하면서 맨 마지막 자리로 이동하는 것이 물방울이 물 위로 올라가는 것 같다고 해서 이름 붙여짐.
Best case(이미 정렬됨): n(n-1)/2
Worst case(역순): 비교와 교환에 n(n-1)/2
Time complexity: O(n^2)
셸 정렬(Shell Sort)
창안자의 이름을 따서 붙여짐.(도널드 셸, Donald L. Shell)
삽입 정렬의 문제점을 보완하기 위한 정렬 방법
- (단점) 인접한 요소만 비교-> 대충 정렬된 리스트에 좋은 성능->역순의 경우 n번의 비교와 이동 필요
-(보안책) h만큼의 간격으로 떨어진 레코드를 삽입 정렬
방법
- 부분 집합의 기준이 되는 간격을 매개변수 h에 저장
- 한 단계가 수행될 때마다 h의 값을 감소, 셸 정렬을 순환 호출
- 일반적으로 h를 원소 개수의 절반 사용
- 단계 수행될 때마다 h의 값을 절반으로 감소시키면서 h가 1이 될 때까지 반복
비교 횟수: h에 의해 결정
Time Complexity: O(n^1.25)
퀵 정렬(Quick Sort)
정렬할 전체 원소에 대해서 정렬을 수행하지 않고, 기준 값을 중심으로 왼쪽 부분 집합과 오른쪽 부분집합으로 분할하여 정렬
-기준 값 피봇(pivot): 일반적으로 가운데에 위치한 원소 선택
- 왼쪽 부분 집합: 기준 값보다 작은 원소를 이동시킴
- 오른쪽 부분 집합: 기준 값보다 큰 원소를 이동시킴
퀵 정렬을 순환적으로 사용: 왼쪽과 오른쪽의 레코드가 서로 독립적으로 정렬
void quickSort(element a[], int left, int right)
{
int pivot, i, j; element temp;
if(left < right) {
i = left; j = right + 1;
pivot = a[left].key;
do {
do i++; while(a[i].key < pivot);
do j--; while(a[j].key > pivot);
if(i < j) SWAP(a[i], a[j],temp);
} while(i < j);
SWAP(a[left], a[j], temp);
quickSort(a, left, j-1);
quickSort(a, j+1, right);
}
}
Worst Case: 피봇에 의해 1:n-1로 치우쳐 분할되는 경우의 반복. Time Complexity: O(n^2)
Average Case: n/2씩 분할되는 경우의 반복. n/2 두개의 서브리스트 정렬과 같음. 레코드 위치시키는데 필요 시간 O(n)
평균 연산 시간 O(nlog_2(n))
합병 정렬(Merge Sort)
여러 개의 정렬된 자료의 집합을 병합하여 한 개의 정렬된 집합으로 만드는 방법
2-way: 2개의 정렬된 자료의 집합을 결합
n-way: n개의 정렬된 자료의 집합을 결합
void merge(element initList[], element mergedList[], int i, int m, int n)
{
int j, k, t; j = m+1; k = i;
while( i <= m && j <= n) {
if (initList[i].key <= initList[j].key)
mergeList[k++] = initList[i++];
else
mergeList[k++] = initList[j++];
}
if (i > m) {
/* mergedList[k:n] = initList[j:n]*/
for(t = j; t <= n; t++)
mergeList[t] = initList[t];
}
else {
/* mergedList[k:n] = initList[i:m] */
for(t = i; t <= m; t++)
mergeList[k+t-i] = initList[t];
}
}
반복 합병 정렬(Iterative Merge Sort): 입력 리스트를 길이가 1인 n개의 정렬된 서브리스트로 간주
반복 합병 정렬 단계
1) 리스트들을 쌍으로 합병하여 크기가 2인 n/2개의 리스트를 얻는다. (n이 홀수이면 하나가 크기 1이 된다.)
2) n/2개 리스트들을 다시 쌍으로 합병하여 n/4개의 리스트를 얻는다.
하나의 서브리스트가 남을 때까지 반복.
void mergePass(element initList[], element mergedList[], int n, int s)
{
for(i = 1; i <= n-2*s+1; i += 2*s)
merge(initList, mergedList, i, i+s-1, i+2*s-1);
if((i + s - 1) < n)
merge(initList, mergedList, i, i+s-1, n);
else
for(j = i; j <= n; j++)
mergedList[j] = initList[j];
}
void mergeSort(element a[], int n)
{
int s = 1; /* 현재 segment 크기 */
element extra[MAX_SIZE];
while (s < n) {
mergePass(a, extra, n, s);
s *= 2;
mergePass(extra , a, n , s);
s *= 2;
}
}
힙 정렬(Heap Sort)
합병 정렬의 문제점: 정렬한 레코드 수에 비례하여 저장공간이 추가적으로 필요
힙 정렬
- 일정한 양의 저장공간만 추가로 필요
- 최악의 경우 연산시간과 평균 연산 시간 O(nlog n)
- 최대 힙(max-heap) 구조 사용
- 최대-힙과 연관된 삭제, 삽입 함수를 이용한 정렬: O(nlog n)
- adjust 함수 사용 - 최대 힙 재조정 O(log n), 이것을 n번 반복
- 왼쪽 및 오른쪽 서브 트리가 모두 힙인 이진 트리에서 시작하여 이진 트리 전체가 최대 힙이 되도록 재조정
- 연산 시간 : O(d) (d는 트리의 깊이, d = log_2(n)
void adjust (element a[], int root, int n)
{
element temp; temp = a[root];
rootkey = a[root].key;
child = 2*root;
while(child <= n) {
if((child < n) && (a[child].key < a[child+1].key))
child++;
if(rootkey > a[child].key) break;
else {
a[child/2] = a[child];
child *= 2;
}
}
a[child/2] = temp;
}
void heapSort(element a[], int n)
{
int i, j;
element temp;
for(i = n/2; i > 0; i--)
adjust(a,i,n);
for(i = n-1; i > 0; i--)
{
SWAP(a[1], a[i+1],temp);
adjust(a, 1, i);
}
}- adjust의 반복 호출로 최대 힙 구조를 만든다
- 힙의 첫 레코드와 마지막 레코드 교환 : 최대 키를 가진 레코드가 정렬된 배열의 정확한 위치에 자리잡게 됨
- 힙의 크기를 줄인 후 힙을 재조정한다.
기수 정렬(Radix Sort)
컴퓨터의 data가 digital(이진수라고) 형태인 것에 착안
어떤 기수 r을 이용하여 정렬: 키를 몇 개의 숫자로 분해
- r=10: Key를 십진수로 분할
- r=2: Key를 이진수로 분할
기수-r 정렬에서는 r개의 bin이 필요
- 레코드가 R1~Rn일 때, 레코드의 key를 기수-r을 이용하여 분할
- 0~(r-1) 사이의 d개의 숫자를 가진 key가 된다
- 각 빈의 레코드는 빈의 첫 레코드를 가리키는 포인터와 마지막 레코드를 가리키는 포인터를 통해 체인으로 연결, 체인은 큐처럼 동작
int radixSort(element a[], int link[], int d, int r, int n)
{
int front[r], rear[r];
int i, bin, current, first, last;
first = 1;
for(i = 1; i < n; i++) {link[i] = i+1;}
link[n] = 0;
for(i = d - 1; i >= 0; i--) {
for(bin = 0; bin < r; bin++) front[bin] = 0;
for(current = first; current; current = link[current]) {
bin = digit[a[current], i, r);
if(front[bin] == 0) front[bin] = current;
else link[rear[bin]] = current;
rear[bin] = current;
}
for(bin++; bin < r; bin++)
if(front[bin]) {link[last] = front[bin]; last = rear[bin]; }
link[last] = 0;
}
return first;
}
트리 정렬(Tree Sort)
binary search tree를 이용하여 정렬
수행 방법
- 정렬할 원소들을 binary search tree로 구성
- binary search tree를 in-order 방식으로 traversal
- in-order traversal -> ascending sort
노드 한 개에 대한 binary search tree 구성 O(log_2(n))
n개 노드에 대한 시간 복잡도: O(n log_2(n))
내부 정렬 요약
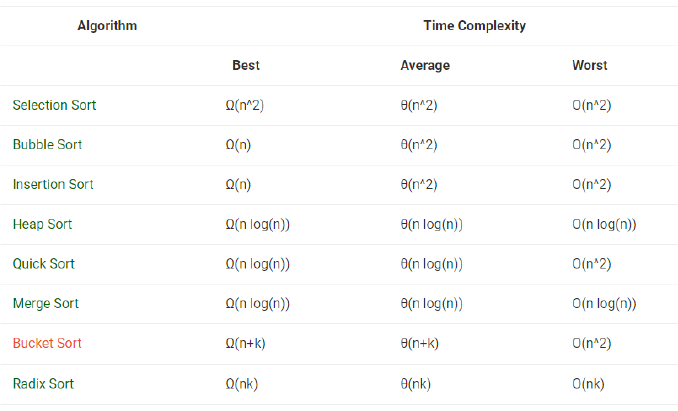
외부 정렬(External Sorting)
정렬하려는 리스트 전체가 컴퓨터의 메모리보다 커서 메모리에 올라갈 수 없다면 내부 정렬을 사용할 수 없음.
블록(block) in DB 시스템
- 한번에 디스크로부터 읽거나 쓸 수 있는 데이터 단위
- 여러개의 레코드로 구성
판독/기록 시간에 영향을 미치는 3가지 요소(HDD 기반)
- 탐구(탐색) 시간(Seek time): 판독/기록 헤드가 디스크 상의 원하는 실린더로 이동하는데 걸리는 시간. 헤드가 가로질러야 하는 실린더 수에 따라 결정
- 회전 지연 시간(Latency time): 트랙의 해당 섹트가 판독/기록 헤드 밑으로 회전해 올 때까지 걸리는 시간
- 전송 시간(Transmission time): 디스크로 또는 디스크로부터 데이터 블록을 전송하는데 걸리는 시간
외부 합병 정렬(External Merge Sort): 외부 저장장치에서 정렬을 할 떄, 가장 널리 알려진 방법
방법
1. 정렬된 run을 구성
입력 리스트의 여러 세그먼트들을 좋은 내부 정렬 방법으로 정렬.(이때 이 세그먼트들을 run이라 함)
run이 생성되면 외부 저장장치에 기록
2. run merge
run들을 하나의 run이 될 때까지 합병 트리 형식을 따라 합병

2원 합병보다 높은 차수의 합병을 이용하면 런에 대해서 일어나는 합병 패스 수를 줄일 수 있다.
입/출력, 합병을 병렬적으로 처리하기 위해서 적당한 버퍼-관리 방법이 필요
패자 트리(loser-tree)를 이용함으로 더 적은 수의 (또는 길이가 더 긴) 런을 만들어 성능 향상을 얻을 수 있음.
k-원 합병

'학교 공부 > 자구(2-1)' 카테고리의 다른 글
| [자료구조] 효율적인 이원 탐색 트리(Efficient Binary Search Trees) (0) | 2025.01.20 |
|---|---|
| [자료구조] 해싱(Hashing) (0) | 2025.01.19 |
| [자료구조] 그래프(Graph) (0) | 2025.01.14 |
| [자료구조] 힙(Heaps) (0) | 2025.01.06 |
| [자료구조] 트리(Trees) (0) | 2025.01.03 |


