
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 운영체제
- 파싱
- 컴파일
- 클래스
- 데이터베이스
- DB
- 언어모델
- docker
- C언어
- Linear Algebra
- 객체지향설계
- 가상메모리
- React
- 스케줄러
- 랩실일기
- 소프트웨어공학
- css
- 웹소프트웨어
- 프로세스
- 자연어처리
- 836
- 자료구조
- 데이터분석
- NLP
- 도커
- OS
- 오픈소스웹소프트웨어
- 파싱테이블
- 컴파일러
- 정보검색
- Today
- Total
observe_db
[정보검색] 7. Scores in a Complete Search System 본문
2. Why rank?
랭킹을 통해 문제를 줄인다.
여러가지 방법들
- Videotape them
- Ask them to "think aloud"
- Interview them
- Eye-track them
- Time them
- Record and count their clicks
그리고 결과를 추적.

결과를 보면(그래프)-
보는거와 클릭하는 것
3. More on cosine
이전의 유사도 계산에서 length normalization을 했다.
거리로 유사도가 흐려지는 것을 방지.
그러나 이래도 문제 발생.
- 문서 크기가 작으면 유사도가 과대평가되고, 문서가 크면 유사도가 과소평가됨.
=>pivot normalization사용
Pivot normalization
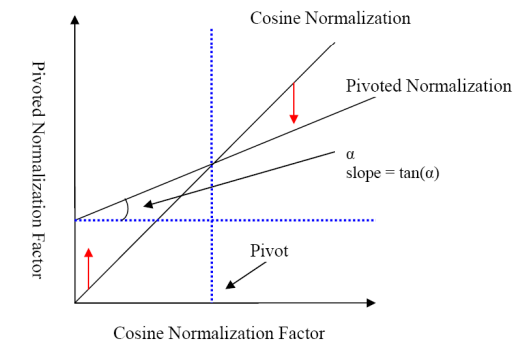
-pivot length를 정하고, 그 길이를 기준(그래프의 pivot이라 적힌 푸른 점선)
-slope=tan(a)를 이용하여
-그 차이값을 이용하여 보정함.
4. The complete search system
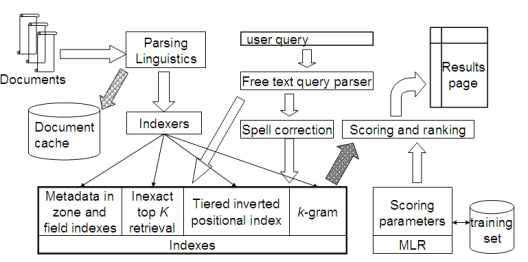
Tiered indexes
기본 아이디어
- 인덱스의 tier들을 만듦
- 높은 티어 인덱스부터 시작.
- 앞부분에서 일정 수(k) 이상의 적중이 나왔으면 중단후 사용자에게 반환
- k보다 적은 hit가 있으면 다음 티어로.
지금까지 다룬 것들
Document preprocessing/Postional indexes/Tiered indexes/Spelling correction/k-gram indexes, wild card, spelling correction/ Query processing/Document scoring...
아직 안한 것들
Document cache: 질의어에 따라 다른 결과
Zone indexes: 어느 위치에 있는지.
ML ranking function
Proximity ranking
Query parser
Vector space retrieval: 문제 제기들
- phrase 검색과 vector space 검색의 결합
- document frequency / idf를 계산하지 않는 이유는?
- Boolean 검색과의 결합
- +와 - 제약조건
- Postfiltering에 대해(쉽지만, 필요하지 않을수도?)--어려운 문제
- wild card와 결합
5. Implementation of ranking
term frequency는 어쨌든 정수형.(빈도가 실수형은 아니니까. 실수형은 다루기 어려움.)
top k in ranking
: 작은 수 k에서 상위 k개.
찾고->정렬하고->상위 리턴.
딱..히 효과적이라고는. min heap을 이용하자.
min heap: binary tree의 값이 그 자식의 것보다 작은 것.
O(N log k)의 복잡도를 가짐.
Ranking은 O(N)의 시간복잡도를 가짐(N은 doc. 갯수)
Optimizer로 줄여도 어쨌든 O(N)
kNN(k-nearest neighbor) 이용.
휴리스틱한 방법
-Reorder posting list
-Heuristics to prune the search space
posting list에서의 Non-docID ordering
이전의 docID에 대한 정렬과 다르게, "goodness"를 측정하는 쿼리 독립적인 척도.
net-score(q, d) = g(d) + cos(q,d)
g = 0~1사이의 값.
좋은거(goodness)를 앞으로
Document-at-a-time(한번에 문서 처리하기)
docID와 PageRank 정렬은 posting list의 doc.들에서 일관성을 부여.
scheme에 cosine을 계산하는 것=doucment-at-a-time
query-doc. 유사도의 계산.
(term-at-a-time processing)
Weight-sorted posting list
: 최종 점수에 기여하지 않는 게시물은 처리하지 않음.
doc. 목록에서 weight에 따른 정렬
정규화된 tf-idf weight(가장 간단. 거의 수행 안함)
top k는 이 정렬된 list의 초반에 생성 가능성 높음.(조기 종료해도 top k 변경 가능성 낮음)
다만
일관된 정렬은 불가능.
doc-at-a-time 불가능.
Term at a time processing
간단한 경우: 첫번째 query term의 posting list를 완전 처리.
accumulator(누산기)를 마주치는 docID마다 생성.
두번째 query term의 posting list 처리.
Accumulators
web(20B doc들)에서는 accumulator를 실행할 수 없음.(posting list에서만 accumulator를 생성 가능)
이것은 'zero score에서 document에 대한 accumulator를 실행하지 말라는 것'과 동일.
Enforcing conjunctive search
모든 term이 발생할 때에 documents에 적용할 수 있음.
'학교 공부 > 정보검색(4-2)' 카테고리의 다른 글
| [정보검색] 9. Relevance Feedback & Query Expansion (0) | 2024.11.19 |
|---|---|
| [정보 검색] 8. Evaluation & Result Summaries (0) | 2024.11.16 |
| [정보 검색] 6. Scoring, Term Weighting, The Vector Space Model (1) | 2024.11.01 |
| [정보 검색] 5. Index Compression (2) | 2024.10.18 |
| [정보검색]4. Index Construction (3) | 2024.10.18 |


