
observe_db
[정보 검색] 8. Evaluation & Result Summaries 본문
2. Introduction
검색 엔진의 평가지표
- 얼마나 인덱스가 빠른지
- 얼마나 빠르게 찾는지
- 쿼리당 비용이 얼마인지
이러한 속도/크기/비용을 수치화 + 사용자 만족도(user happiness)도 주요함.
Factor들은 이러한 것들을 포함한다.
- 응답 속도
- 인덱스 크기
- uncluttered UI
- 'relevance'(관련 있는지)
- 무료인가?
사용자(USER)에 대한 정의
searcher(검색자): 빨리 결과가 나오면 좋아함
advertiser(광고자): 많이 클릭하면 좋아함
buyer(구매자): 많이 구매하면 좋아함
seller(판매자): 많이 판매하면 좋아함
CEO: 회사의 이익/일이 효율적이면 좋아함
사용자 만족도 == 쿼리의 결과가 얼마나 연관있는지.(relevance)
그렇다면 어떻게 relevance를 측정하는가?
- benchmark document collection
- benchmark suite of queries
- assessment of the relevance of each query-document pair
Query와 information need
information need는 의도에 가까움.
query는 실제로 검색엔진에 넣는 말.
ex. '정보검색에서 검색 엔진의 성능을 어떻게 판단하는지를 찾고싶다.'가 information need
ex. '정보검색 검색엔진 성능 지표'나 '성능 판단' 은 query
때문에 사용자 만족도는 information need를 얼마나 충족하는가에 달림.
3. Unranked evaluation

여기서 Precision과 Recall이 나온다.
사실 위의 표는 데이터 예측에 맞춰져 있는데, 실제값-관련 여부/ 예측값-검색 여부로 바꾸어 생각하면 된다.
P = TP/ (TP+FP) ... 검색된 것들 중 관련있는게 얼마나 있는지(=P(relevant|retrieved)
R = TP / (TP+FN) ... 관련 있는것을 얼마나 검색으로 뽑아냈는지.(=P(retrieved|relevant)
F score
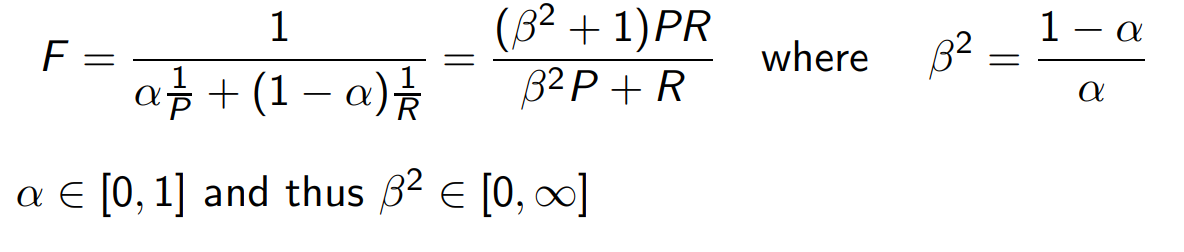
수식은 위와 같다.
보통 균형있게 하면 B=1, a=0.5로 설정.
대중적인 accuracy(정확도)도 있다.
(TP+TN) / (TP+FP+TN+FN) -- 제대로 함/전체
단점은 전체가 커지면 관련 있고, 검색되는거도 줄어들어서, 큰 의미가 없어진다.
4. Ranked Evaluation
Precision, recall, F는 모두 unranked set을 측정하는데 사용
ranked list도 생각해야함.
precision-recall curve를 사용함.
검색 결과가 늘어나면
Recall은 증가 추세.
Precision은 오락가락하며 감소.
ROC curve

specificity(특이도): 실제 관련 없는 것들을 얼마나 걸러냈는지.(TN / (FP+TN))
그래서 1-specificity는 '실제 관련 없는 것들을 얼마나 걸러내지 못했는지' (FP/ (FP+TN))
5. Benchmarks
필요한 사항
document들의 collection: (대표할 수 있는) 문서들의 모음
information need들의 collection
사람의 평가(assessment)-judges
Cranfield
TREC(트랙, Text Retrieval Conference)
ClueWeb09: 1B 크기
일관되야 사용.(그렇지 않으면 truth하다 보기 어려움+재현 어려움.)
이 일관성을 위해 Kappa measure 사용
Kappa measure
문서를 줄 때에 관련 여부 판단이 일치/불일치 하는지.

P(A)는 관련에 대해 일치할 확률
P(E)는 우연히 맞출 확률
보통 κ는 [2/3, 1.0]정도의 범위
relevance check에서 의견이 갈리는게 있어도, 전체 순위에 큰 영향은 없음.
A/B testing
검색 엔진의 테스트
입력의 일부분(1%정도)을 새로운 모델로 줘서 평가.
ex. 첫클릭이 무엇인지 등등.
6. Result summaries
질의어 요약(두줄 정도로?)
1) static 2) dynamic
static summaries
-가장 간단한 휴리스틱: 앞의 50단어를 이용
-좀더 정교하게: 각 document에서 'key sentence'를 추출
-좀더 정교하게: 복잡한 NLP 기술-summary 합성/생성
dynamic summaries
window 또는 "snippet"을 사용
검색하면 나오는 아래의 query의 단어들이 포함된 문장들 일부를 보여주는 것이 snippet
예시

여기서 저 아래에 뜨는 <정보검색....이란, 수집된...>과 <정보 검색... 은 집합적인...>이 snippet이다.
관련도가 높은 부분을 보여주며, query에 따라 보여주는 문서 부분에 차이가 있다.
'학교 공부 > 정보검색(4-2)' 카테고리의 다른 글
| [정보검색] 10. Web Search & Link Analysis (2) | 2024.11.22 |
|---|---|
| [정보검색] 9. Relevance Feedback & Query Expansion (0) | 2024.11.19 |
| [정보검색] 7. Scores in a Complete Search System (0) | 2024.11.08 |
| [정보 검색] 6. Scoring, Term Weighting, The Vector Space Model (1) | 2024.11.01 |
| [정보 검색] 5. Index Compression (2) | 2024.10.18 |



