
observe_db
[정보검색] 9. Relevance Feedback & Query Expansion 본문
2. Motivation
Recall 개선하기: 동의어, 유의어들 추출.
ex. aircraft라는 query에 대해서 plane의 결과물도 넣는다면?
두가지 방법
1. Local- relevance feedback
2. thesaurus- query expansion
3. Relevance feedback: Basics
사용자 피드백을 이용해서 다시 검색
처음 검색->사용자가 관련 있는 것들을 선택->그 feedback 기반으로 다시 검색.
4. Relevance feedback: Details
Centroid: 질량의 중심점(point)
def.
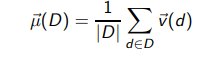
D는 document 집합, v(d)는 벡터
Rocchoi algorithm
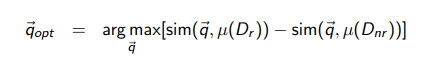
q_opt를 최대화하는 것.
Dr: 관련있는 docs
Dnr: 관련 없는 docs
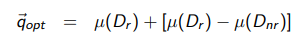
이렇게 다시 쓸 수 있음.
조금 나아가서 가중치 α,β,γ를 이용하여 수정 가능
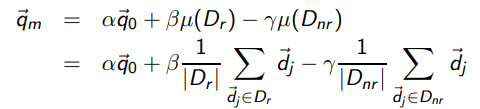
Relevane feedback의 기본 추정
- 이니셜 쿼리는 유효할 것이다.
->사용자와 collection의 용어가 차이날 수도 있다.(유효하기 어려움)
- 유사한 term들이 선택되어 구분될 것이다.
->관계가 있음에도 구분되는 경우도 있다.
평가 방법
top 10개 precision : P@10
feedback을 한 것들은 이미 답을 알려주었으니까 그것들을 제외하고 평가해야 공정.
Caveat: 시스템에서 질의하고 상위 문서로 확장(시간을 동일하게 하기 위함).
문제점
: 쿼리가 많다.
Pseudo-relevance feedback
시스템이 알아서 relevant feedback.
'평균적'으로 좋음.(query drift같은것으로 확 꺾이기도 해서..)
5. Query Expansion
사용자 피드백의 종류
-document(relevance feedback에서 많음)
-words or phrase (query expansion에서 많음)
Query expansion
- 쿼리를 좀 넓게 적용해서 결과를 다양화
- 유사한 개념 중심의 '시소러스' 활용
Thesaurus-based query expansion
- 유사어모음을 통해 검색이 용이
-양이 많아지니 Recall은 높아지지만 precision은 떨어질 수도 있음.
'학교 공부 > 정보검색(4-2)' 카테고리의 다른 글
| [정보 검색] 11. Test Classification & Naive Bayes (0) | 2024.11.28 |
|---|---|
| [정보검색] 10. Web Search & Link Analysis (2) | 2024.11.22 |
| [정보 검색] 8. Evaluation & Result Summaries (0) | 2024.11.16 |
| [정보검색] 7. Scores in a Complete Search System (0) | 2024.11.08 |
| [정보 검색] 6. Scoring, Term Weighting, The Vector Space Model (1) | 2024.11.01 |



